Blog
Data Science, Industry Insights
Data Science • Published on March 4, 2020
Startups usually iterate rapidly when exploring new approaches to solve problems. One pitfall of the hectic pace is overlooking small decisions that might have big impacts later, especially when product requirements and constraints evolve.
Let’s deep dive into a real-life example found when we improved the Convoy experimentation service, which helps product teams conduct controlled experiments or A/B tests. On the surface, making control vs. treatment assignments should be a trivial task. But, the quality of the assignment process had a fundamental impact on the outcome of the experiments.
Previously, our assignment algorithm worked like this:
the weight of control: W(c) = 4the weight of the treatment: W(t) = 1
2. We summed up weights of all variants to get total weight,
W = W(c) + W(t) = 5
3. We generated an integer H = Hash(exp, e) for entity e in this experiment exp, say
H = Hash(exp, e) = 987654674
4. We used the modulo function
Mod(H, W) = 4
5. Finally, we randomly assigned integers in [0, W-1] to control or treatment according to the weight ratio.
6. For this example, let’s assume mod result [0, 1, 2, 3] would be assigned to control and [4] would be assigned to treatment. Hence, we would assign entity e to treatment for this experiment.
This algorithm worked fine until the product teams took a gradual rollout approach to mitigate the risk of bad experiments. In this iterative approach, the product teams wanted to put a small percentage of the population on treatment and leave the rest in control in the initial version. They wanted to shut down the experiment early if the treatment showed disappointing results. If the treatment looked reasonably good, they would shift more population to treatment. We identified each such shift as a new version of the same experiment.

When this experiment went from v0 to v1, the mod function Mod(H, W) gave a different result for the same entity e. There was no guarantee that entity e would be assigned to treatment in v1. But an entity previously assigned to treatment should not be reverted to control while we roll out treatment to more entities. More importantly, the experiment results would get polluted due to these flips.
To avoid flipping assignments, the experiment upgrade process had to decide which assignment decisions to carry forward to the next version, and which to overwrite due to the weight change. This memorization based process also could not survive over two generations. Things got even more complicated if an experiment had more than two variants.
This cross-version assignment process was nondeterministic and nearly impossible to validate. Bugs were hard to investigate and fix. The complexity also rendered the system more fragile and subject to operational issues in the production environment.
After investigating a few assignment quality issues, we redesigned our assignment solution for full transparency with two dead simple steps that are repeatable and verifiable.
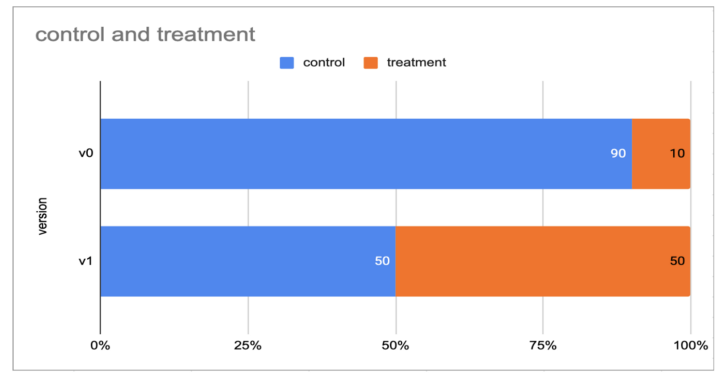
Each of the two steps above is transparent and auditable. While simplicity resulted in a more robust system, we also reduced storage and serving cost because we no longer need to carry individual assignments forward to the next version.
But wait, how would this work for experiments with more than 2 variants? For example,

How were we going to change the bucket allocation when upgrading from v0 to v1? Would this work?
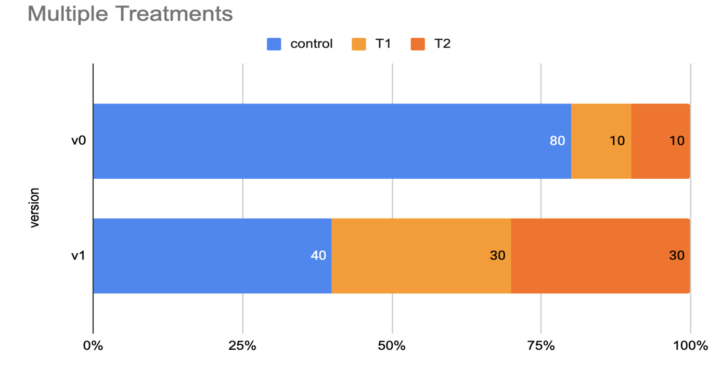
The population in the T2 buckets of v1 would include some entities from T1 of v0. This was not acceptable because these entities would have been exposed to both treatments and that could invalidate the experiment results.
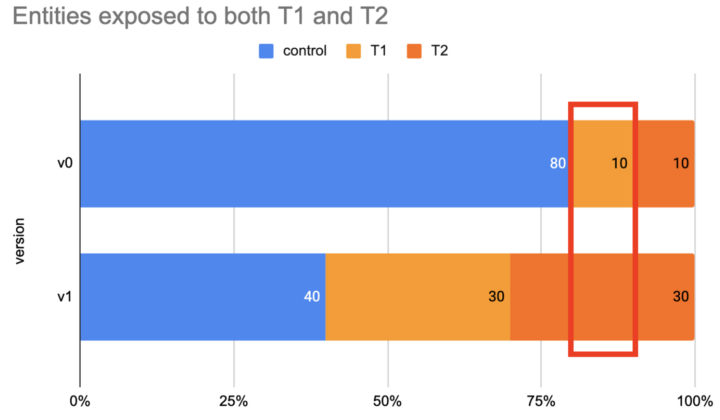
To solve this problem, we came up with this new approach which allows us to scale up and down comfortably until we are ready to declare a winner among the treatments. Each treatment will have a dedicated range of buckets to expand and retract. This guaranteed that an individual entity won’t be exposed to multiple treatments before a winner is declared.
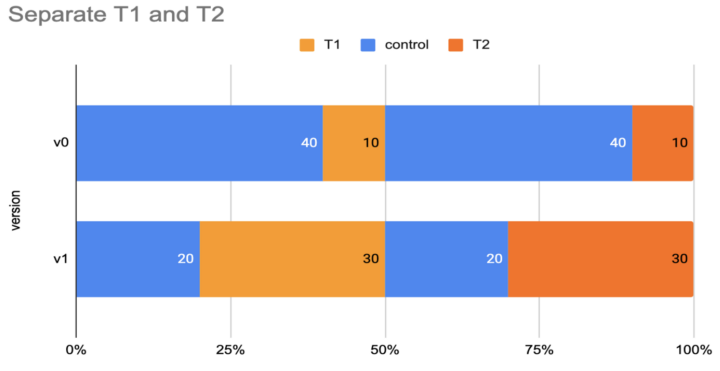
To accommodate more complicated scenarios, bucket allocation could also be edited manually. Notice that manual allocation of the buckets would not affect the randomness of the assignments because step one already took care of the randomization at the experiment level.
If you enjoyed this deep dive, consider joining Convoy. We are actively advancing technology to address the hard challenges of making assignments. For example, here are a few deeper assignment problems that are relevant to a company like Convoy with a unique marketplace.
Convoy is on a mission to reduce billions of miles driven empty in the freight industry. Innovation through experimentation is how we roll. Improper assignments waste precious engineering resources, slow down the experimentation flywheel, or even lead us down the wrong path. How we do assignments is a small decision with a BIG impact!