Blog
Data Science, Industry Insights
Data Science • Published on December 14, 2021
At Convoy, we know that service quality is a top concern for the companies that entrust us to move their goods. Our aim is to always fulfill their needs, but sometimes unforeseeable events happen that prevent the trucking companies in our network from picking up or delivering on-time. For instance, trucks can be delayed at a prior facility, break down during transit, or run into unexpected traffic.
One of our customer service standards is to notify a shipper as soon as possible of an anticipated failure to arrive on time. To enable this notification, and to give ourselves time to reschedule appointments if necessary, we built a model to predict the risk of a service failure. As is common in machine learning, there are a number of possible ways to solve this problem, but the choice of tool can have large implications on the outcome.
From a statistics and machine learning perspective, this challenge can be addressed by either a regression model to predict when the driver will arrive, or by a classification model to predict simply whether a driver will arrive on time or late.
There are a large number of reasons a driver may be late, which makes predicting a precise arrival time challenging when something has gone wrong. How long will it take to fix the mechanical problem? If the driver is stuck trying to drop off a previous load, when will they get unstuck?
Convoy, and even the drivers themselves, sometimes lack enough information in these cases to accurately predict the time a driver will arrive. Predicting arrival times in these uncertain conditions is very challenging, but fortunately it’s not usually necessary.
For Convoy and for the shippers we work with, the risk of failure is the most crucial aspect to understand. We don’t need to know exactly when the driver is going to arrive, but we do need to know when to raise an alert and whether their appointment should be rescheduled. A classifier is more directly tied to the business problem and the outcome we want to influence. It is also the lesser included case of this problem: if we know it’s tough to predict arrival time, and we don’t actually need it, we should tackle the easier problem of late vs on time. By training a binary classifier with data labeled as “late” or “not late”, we can predict the probability of the driver being late. If this probability exceeds a threshold we set, we can raise an alert and reschedule the appointment to avoid a more significant service failure.
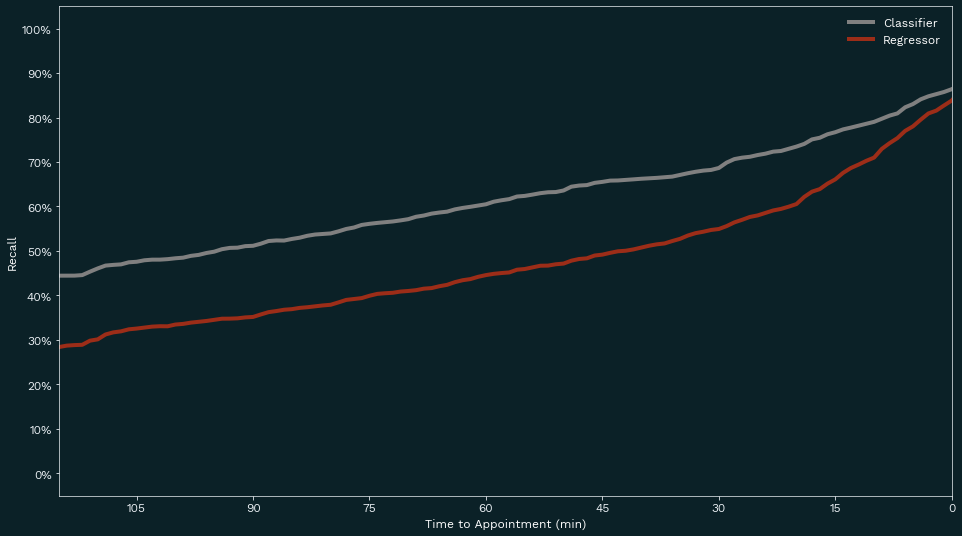
We can directly compare the performance of these two approaches to this business problem. In the example pictured above, both models are using the same set of features. The regressor raises an alert if it predicts the driver will arrive after the appointment time. The classifier’s threshold was chosen to match the precision of the alerts that were raised by the regressor. With the same precision, we see that the classifier detects more late shipments than the regressor does at any time before the appointment.
A classifier that uses log loss as a loss function performs better here because it more directly optimizes for the business problem and metrics of interest: precision and recall. Alternatively, the loss function for the regressor, root mean squared error (RMSE), is disconnected from the underlying business goal. Consider two examples:
Minimizing RMSE provides us with the most reliable model for predicting arrival times, but it is not the best approach to predict whether or not the carrier will be late.
Also beneficial, with a classification model we can easily tune our alerting threshold to adjust our false positive and false negative rates. We can minimize our operating costs using the respective costs of these two types of error. This is a more challenging task with a regressor unless we have a clear understanding of its error distribution.
By choosing an approach that is directly tied to the business problem, and limiting the information we’re trying to predict to only what we need for our decision making, we gain more flexibility and a clearer picture of how to optimize this part of our business. There’s always more than one way to solve a problem.